🔥 Local-Cloud Inference Offloading for LLMs in Multi-Modal, Multi-Task, Multi-Dialogue Settings
Abstract
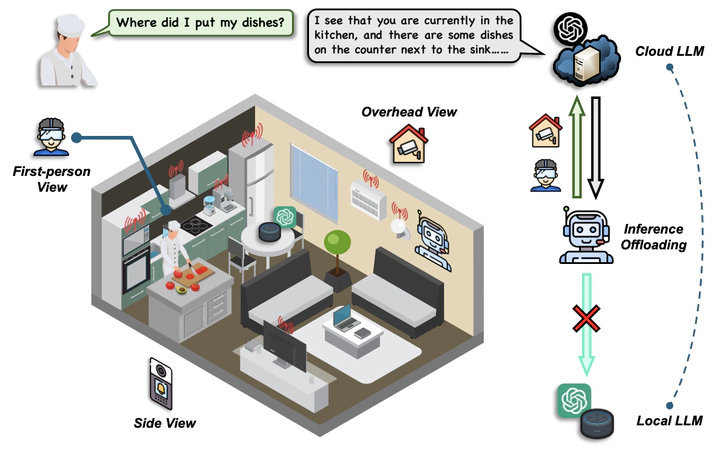
Compared to traditional machine learning models, recent large language models (LLMs) can exhibit multi-task-solving capabilities through multiple dialogues and multi-modal data sources. These unique characteristics of LLMs, together with their large model size, make their deployment more challenging. Specifically, (i) deploying LLMs on local devices faces computational, memory, and energy resource issues, while (ii) deploying them in the cloud cannot guarantee real-time service and incurs communication/usage costs. In this paper, we design TMO, a local-cloud LLM inference system with Three-M Offloading: Multi-modal, Multi-task, and Multi-dialogue. TMO incorporates (i) a lightweight local LLM that can process simple tasks at high speed and (ii) a large-scale cloud LLM that can handle multi-modal data sources. We develop a resource-constrained reinforcement learning (RCRL) strategy for TMO that optimizes the inference location (i.e., local vs. cloud) and multi-modal data sources to use for each task/dialogue, aiming to maximize the long-term reward (response quality, latency, and usage cost) while adhering to resource constraints. We also contribute M4A1, a new dataset we curated that contains reward and cost metrics across multiple modality, task, dialogue, and LLM configurations, enabling evaluation of offloading decisions. We demonstrate the effectiveness of TMO compared to several exploration-decision and LLM-as-Agent baselines, showing significant improvements in latency, cost, and response quality.