Iterative Critique-and-Routing Controller for Multi-Agent Systems with Heterogeneous LLMs
Abstract
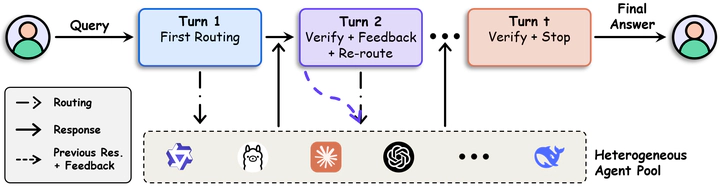
Multi-agent large language model (LLM) systems often rely on a controller to coordinate a pool of heterogeneous models, yet existing controllers are typically limited to one-shot routing: they select a model once and return its output directly. Such routing-only designs provide no mechanism to critique intermediate drafts or support iterative refinement. To address this limitation, we propose a critique-and-routing controller that casts multi-agent coordination as a sequential decision problem. At each turn, the controller evaluates the current draft, decides whether to stop or continue, and, if needed, selects the next agent for further refinement. We formulate this process as a finite-horizon Markov Decision Process (MDP) with explicit agent-utilization constraints, design a composite reward for controller decisions across turns, and optimize the controller via policy gradients under a Lagrangian-relaxed objective. Extensive experiments across multiple heterogeneous multi-agent systems and seven reasoning benchmarks show that our method consistently outperforms state-of-the-art baselines and substantially narrows the gap to the strongest agent, while using it for fewer than 25% of total calls.