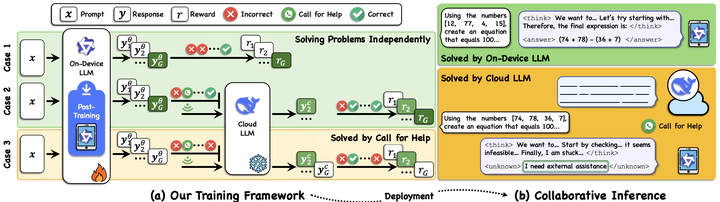
Abstract
Device-cloud collaboration has emerged as a promising paradigm for deploying large language models (LLMs), combining the efficiency of lightweight on-device inference with the superior performance of powerful cloud LLMs. An essential problem in this scenario lies in deciding whether a given query is best handled locally or delegated to the cloud. Existing approaches typically rely on external routers, implemented as binary classifiers, which often struggle to determine task difficulty from the prompt’s surface pattern. To address these limitations, we propose a framework where the on-device LLM makes routing decisions at the end of its solving process, with this capability instilled through post-training. In particular, we formulate a reward maximization problem with carefully designed rewards that encourage effective problem solving and judicious offloading to the cloud. To solve this problem, we develop a group-adaptive policy gradient algorithm, featuring a group-level policy gradient, designed to yield an unbiased gradient estimator of the reward, and adaptive prompt filtering, developed to enforce the constraint on cloud LLM usage. Extensive experiments across models and benchmarks show that the proposed methodology consistently outperforms existing baselines and significantly narrows the gap to full cloud LLM performance.